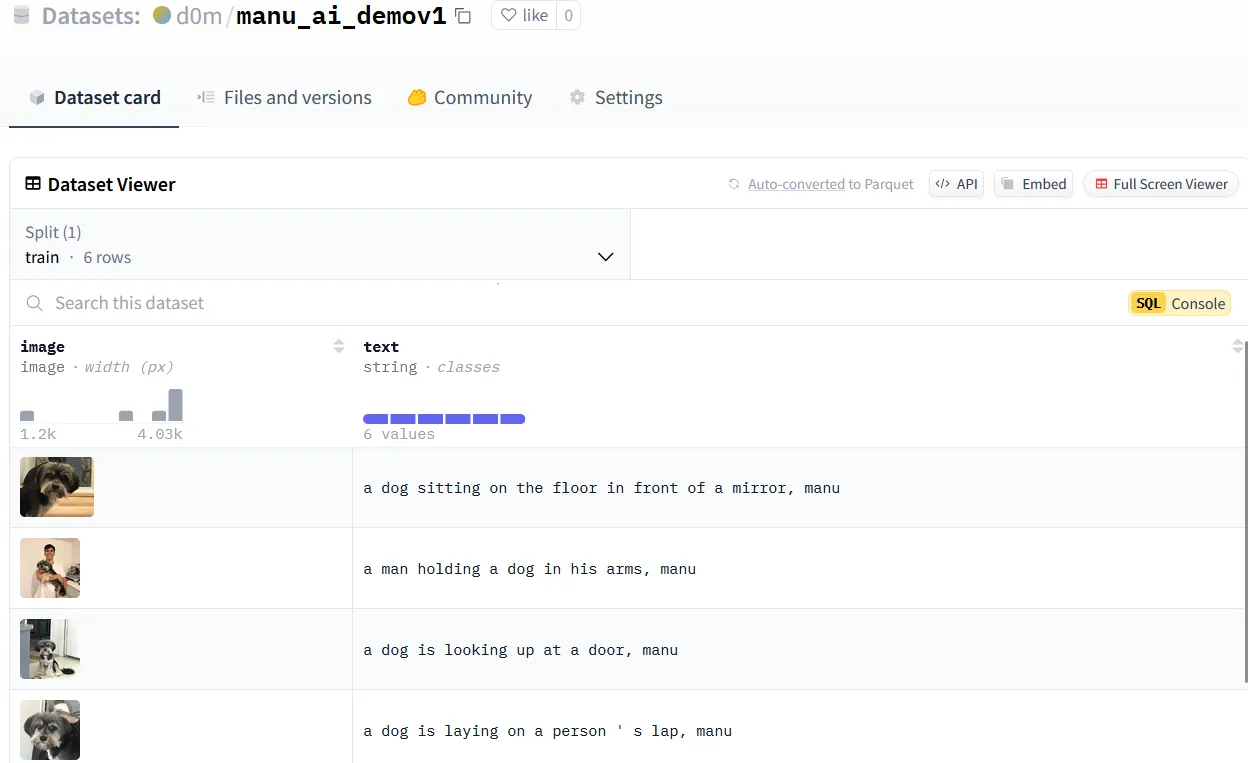
Auto image captioning with AI models
Auto image captioning with AI models
Image captions from Blip model
Microsoft Florence-2
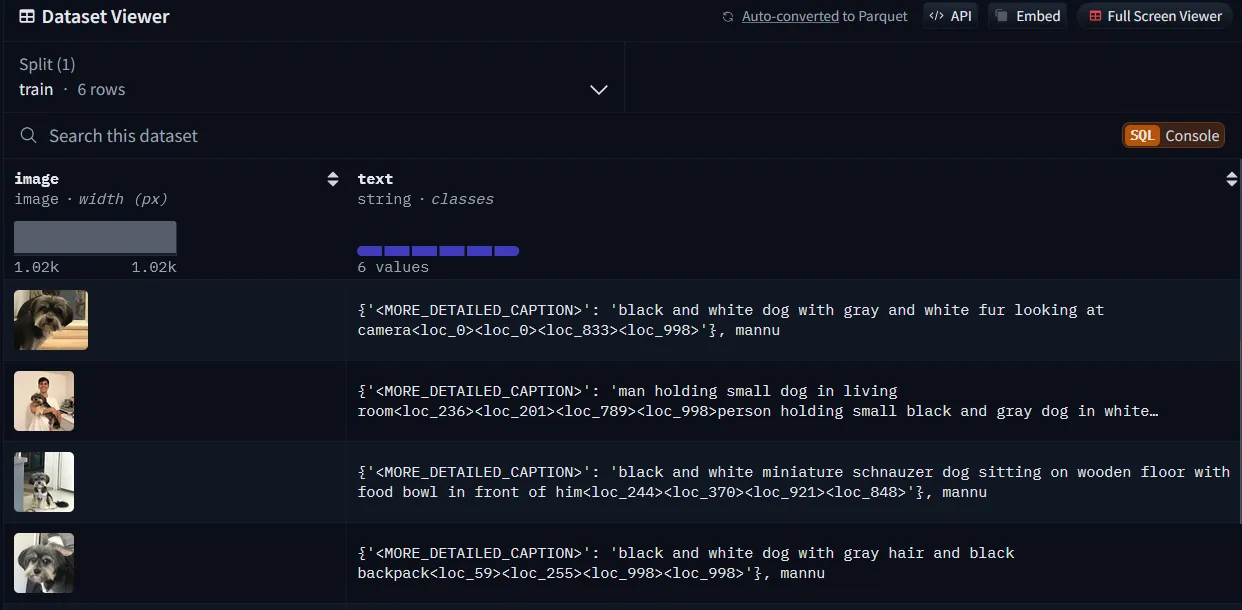
The special tokens like <loc_number> in the output of the Microsoft Florence-2-large model typically indicate spatial location information or features related to the image’s content. These tokens are part of Florence’s structured output format, which encodes visual grounding information.
Explanation of <loc_number> Tokens
-
Purpose:
- Florence is designed to support multimodal tasks, such as visual question answering and grounded image captioning. The
<loc_number>tokens are used to provide a link between textual descriptions and specific regions or objects in the image.
- Florence is designed to support multimodal tasks, such as visual question answering and grounded image captioning. The
-
Functionality:
- The tokens like
<loc_0>,<loc_833>, etc., are placeholders that correspond to regions detected in the image. These regions are typically outputs of the visual backbone model that processes the image into a set of objects, bounding boxes, or semantic areas.
- The tokens like
-
Why You See Them:
- When the model generates text, it may include these
<loc_number>tokens to indicate that certain parts of the description relate to specific image regions. This can occur if the task’s prompt or decoding settings allow raw outputs with such tokens. - For example, if you don’t specify a clear captioning-only task, Florence might leave these tokens in the output instead of post-processing them out.
- When the model generates text, it may include these
-
How to Handle Them:
- Florence’s
processor.post_process_generationmethod is designed to process and clean up these tokens, converting them into human-readable descriptions or removing them for standard captioning tasks. If you still see them in the output, ensure that:- The
taskparameter inpost_process_generationis set appropriately (e.g., for captioning tasks, it should be left empty or specified as"image_captioning"). - Your
post_process_generationfunction is invoked correctly.
- The
- Florence’s
Trim Grounding tokens (if you only care about captions)
Ensure the post_process_generation step explicitly removes these tokens for plain captions:
parsed_answer = processor.post_process_generation(
generated_text,
task="<OD>", # Explicitly set the task for captioning
# 'task' docs : https://huggingface.co/microsoft/Florence-2-large#tasks
image_size=(image.width, image.height)
)If the task parameter does not remove these tokens, you can manually filter them out:
cleaned_caption = re.sub(r"<loc_\d+>", "", parsed_answer).strip()When Should You Keep <loc_number> Tokens?
- For visual grounding or multimodal tasks where precise references to image regions are required, these tokens are valuable.
- If you’re only interested in pure captioning (like in your case), you should remove or ignore these tokens.
Further Details
The <loc_number> tokens are detailed in Florence’s documentation on Hugging Face, where they represent object region identifiers from the model’s image feature extractor. This mechanism enables Florence to link textual descriptions directly to visual components in tasks like object localization and referential comprehension.